
مفاهیم و مقدمات سئو
۱۴۰۰-۰۶-۰۷
یافتن کلمات کلیدی
۱۴۰۰-۰۶-۰۷موتورهای جستجو چگونه کار می کنند: خزیدن “Crawling”، نمایه سازی “Indexing” و رتبه بندی “Ranking”

راهنمای مبتدی برای سئو
همانطور که در فصل ۱ اشاره کردیم، موتورهای جستجو ماشین پاسخ هستند. آنها برای کشف، درک و سازماندهی محتوای اینترنت به منظور ارائه مناسب ترین نتایج به سوالاتی که جستجوگران می پرسند، بوجود آمدند.
برای نمایش در نتایج جستجو، ابتدا باید محتوای شما برای موتورهای جستجو قابل مشاهده باشد. این بدون شک مهمترین قطعه پازل سئو است: اگر سایت شما پیدا نشد ، به هیچ وجه نمی توانید در SERPs (صفحه نتایج موتورهای جستجو) ظاهر شوید.
موتورهای جستجو چگونه کار می کنند؟
موتورهای جستجو از طریق سه عملکرد اصلی کار می کنند:
- خزیدن”Crawling”: برای جستجوی محتوا ، اینترنت را جستجو کنید ، برای هر نشانی اینترنتی که پیدا می کنید ، کد یا محتوا را جستجو کنید.
- فهرست بندی “Indexing” : محتوای موجود در فرآیند خزیدن را ذخیره و سازماندهی کنید. هنگامی که صفحه ای در فهرست قرار می گیرد، در حال اجرا است تا در نتایج به درخواست های مربوطه نمایش داده شود.
- رتبه بندی “Ranking” : قطعاتی از محتوا را ارائه دهید که به بهترین نحو به سئوال یک جستجوگر پاسخ دهند، این بدان معناست که نتایج با توجه به ارتباط خود به سوال جستجوگر از بیشترین ارتباط به سمت کمترین ارتباط مرتب می گردند.
خزیدن موتور جستجو چیست؟
خزیدن”Crawling” فرایندی است که طی آن موتورهای جستجو تیمی از روبات ها (معروف به خزنده یا عنکبوت) را برای یافتن محتوای جدید و به روز ارسال می کنند. محتوا می تواند متفاوت باشد – ممکن است یک صفحه وب ، یک تصویر ، یک فیلم ، یک PDF و غیره باشد – اما صرف نظر از قالب ، محتوا توسط پیوندها کشف می شود.
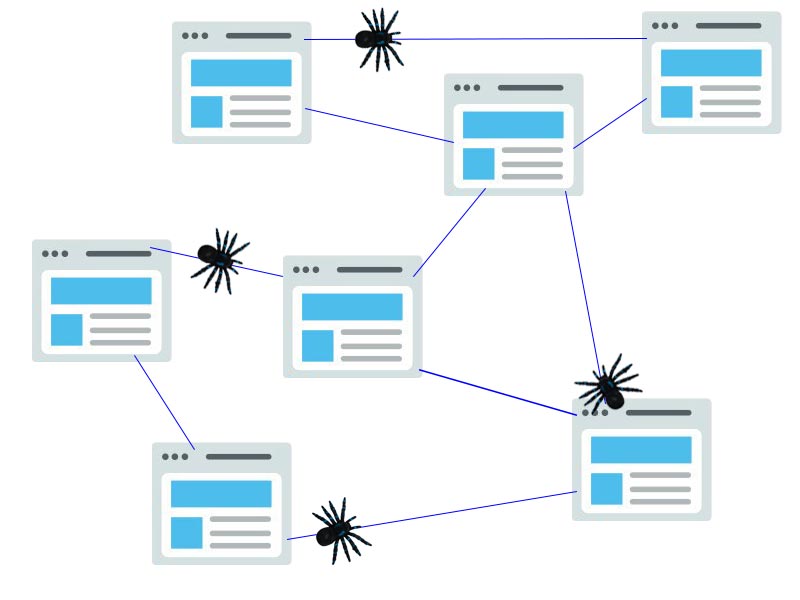
ربات های گوگل “Googlebot” با واکشی چند صفحه وب شروع به کار می کند و سپس پیوندهای موجود در آن صفحات وب را برای یافتن آدرس های اینترنتی جدید دنبال می کند. با پرش در این مسیر پیوندها ، خزنده قادر است محتوای جدیدی را بیابد و آن را به فهرست خود بنام کافئین “Caffeine” – پایگاه داده عظیم آدرس های اینترنتی کشف شده – اضافه کند تا بعداً هنگامی که جستجوکننده به دنبال اطلاعاتی است که محتوای آن آدرس اینترنتی است، بازیابی شود.
فهرست”index” موتورهای جستجو چیست؟
موتورهای جستجو اطلاعاتی را که در ایندکس پیدا می کنند پردازش و ذخیره می نمایند. پایگاه داده عظیمی از تمام محتواهایی که کشف کرده اند و به نظر می رسد به اندازه کافی برای جستجوگران مناسب است. این اطلاعات شامل تمام صفحات و اطلاعاتی است که در وب سایت ها قابل دسترسی برای موتورهای جستجو هستند.
رتبه بندی موتورهای جستجو
وقتی شخصی جستجو را انجام می دهد، موتورهای جستجو مطالب فهرست “ایندکس” شده خود را برای محتوای بسیار مرتبط جستجو می کنند و سپس به امید حل پرس و جوی جستجوگر، آن محتوا را سفارش می دهند. این ترتیب نتایج جستجو بر اساس ارتباط ، به عنوان رتبه بندی شناخته می شود. به طور کلی ، می توانید فرض کنید که هرچه یک وب سایت رتبه بالاتری داشته باشد ، موتور جستجو معتقد است که این سایت با پرس و جو مرتبط تر است.
ممکن است خزنده های موتور جستجو را از بخشی یا تمام سایت خود مسدود کنید، یا به موتورهای جستجو دستور دهید از ذخیره صفحات خاصی در فهرست خود اجتناب کنند. اگرچه دلایلی برای انجام این کار وجود دارد، اما اگر می خواهید محتوای شما توسط جستجوگران پیدا شود، ابتدا باید مطمئن شوید که برای خزنده ها قابل دسترسی است و ایندکس شده است. در غیر این صورت ، به همان اندازه نامرئی است.
در پایان این فصل ، شما زمینه ای را خواهید داشت که برای کار با موتور جستجو لازم دارید ، نه بر خلاف آن!
در سئو ، همه موتورهای جستجو یکسان نیستند
بسیاری از مبتدیان از اهمیت نسبی موتورهای جستجوی خاص می پرسند. اکثر مردم می دانند که گوگل بیشترین سهم بازار را دارد ، اما بهینه سازی برای بینگ ، یاهو و دیگران چقدر اهمیت دارد؟ حقیقت این است که علی رغم وجود بیش از ۳۰ موتور جستجوی وب اصلی ، جامعه سئو واقعا به گوگل توجه می کند. چرا؟ پاسخ کوتاه این است که گوگل جایی است که اکثر مردم در وب جستجو می کنند. در گوگل ایمیج ، گوگل مپ و یوتوب یا هریک از ویژگی های گوگل بیش از ۹۰ درصد جستجوهای وب انجام می شود – این تقریباً ۲۰ برابر بینگ و یاهو است.
خزیدن “Crawling”: آیا موتورهای جستجو می توانند صفحات شما را پیدا کنند؟
همانطور که تازه آموخته اید ، مطمئن شوید که سایت شما خزیده و نمایه می شود، این یک پیش نیاز برای نمایش در SERP ها است. اگر از قبل وب سایت دارید ، بهتر است با دیدن تعداد صفحات خود در فهرست شروع کنید. با این کار می توانید بینش های خوبی راجع به اینکه آیا گوگل در حال خزیدن است و همه صفحاتی را که می خواهید پیدا کند یا خیر ، پیدا کنید.
یک راه برای بررسی صفحات نمایه شده شما “site: yourdomain.com” است. یک اپراتور جستجوی پیشرفته . به گوگل بروید و “site: yourdomain.com” را در نوار جستجو تایپ کنید. گوگل این نتایج را به شما نشان خواهد داد که مربوط به فهرست سایت مورد نظر شماست :
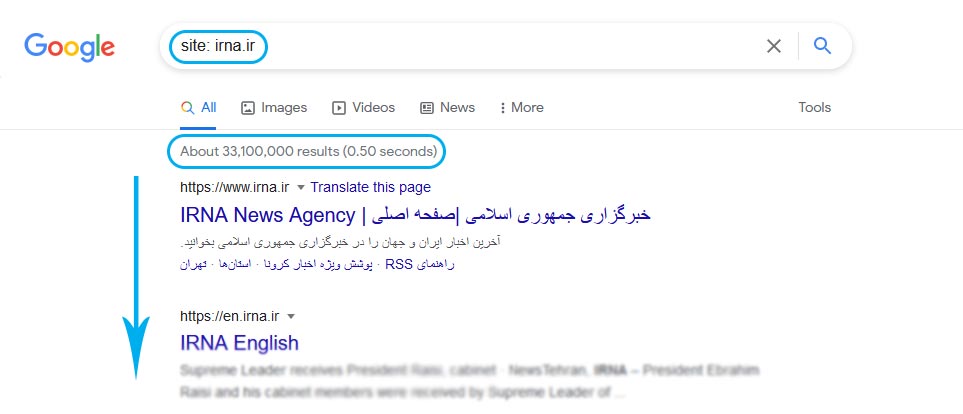
تعداد نتایجی که گوگل نمایش می دهد (به “تعداد نتایج بدست آمده ” در بالای صفحه جستجو مراجعه کنید) دقیق نیست، اما به شما این ایده را می دهد که کدام صفحات در سایت شما نمایه “ایندکس”شده اند و چگونه در حال حاضر در نتایج جستجو نشان داده می شوند.
برای نتایج دقیق تر، گزارش پوشش فهرست “Index Coverage report” را در گوگل سرچ کنسول مشاهده و استفاده کنید. اگر در حال حاضر یک حساب گوگل سرچ کنسول ندارید ، می توانید ثبت نام کنید. با استفاده از این ابزار ، می توانید نقشه های سایت خود را برای گوگل ارسال کرده و تعداد صفحات ارسال شده را به سایر موارد در فهرست گوگل اضافه کنید.
اگر در هیچ جایی از نتایج جستجو ظاهر نمی شوید ، چند دلیل ممکن است وجود داشته باشد:
- سایت شما کاملاً جدید است و هنوز خزیده نشده است.
- سایت شما به هیچ وب سایت خارجی پیوند ندارد.
- ناوبری سایت شما باعث می شود که یک روبات نتواند به طور مؤثر در آن بخزد.
- سایت شما شامل برخی از کد های اصلی به نام دستورالعمل های خزنده “Crawler directives” است که موتورهای جستجو را مسدود می کند.
- سایت شما به دلیل تاکتیک های ناخواسته توسط گوگل مجازات شده است.
نحوه خزیدن “crawl” در سایت خود را به موتورهای جستجو توضیح دهید
اگر از گوگل سرچ کنسول (Google Search Console) یا اپراتور جستجوی پیشرفته “site: domain.com” استفاده کرده اید و متوجه شده اید که برخی از صفحات مهم شما در فهرست گم شده اند و یا برخی از صفحات بی اهمیت شما به اشتباه فهرست بندی (ایندکس) شده اند، می توانید برخی از بهینه سازی ها را برای آن انجام دهید و مشکل را برطرف نمایید. بهینه سازی هایی برای هدایت بهتر ربات های گوگل (Googlebot) جهت خزیدن بهتر در وب سایت شما. اینکه به موتورهای جستجو اعلام نمایید که چگونه سایت شما را ایندکس (فهرست) کنند، می تواند موجب بدست آوردن نتایج بهتری در ایندکس (فهرست بندی) سایت شما داشته باشد.
اکثر مردم به این فکر می کنند که گوگل بتواند صفحات مهم وب سایت آنها را پیدا کند. اما به راحتی فراموش می کنند که احتمالاً صفحاتی وجود دارد که نمی خواهند ربات های گوگل آنها را پیدا کند. این موارد ممکن است شامل مواردی مانند پیوندهای قدیمی با محتوای نازک ، پیوندهای تکراری (مانند پارامترهای مرتب سازی و فیلتر برای تجارت الکترونیکی) ، صفحات کد تبلیغاتی ویژه ، صفحات مرحله بندی یا آزمایشی و غیره باشد.
برای هدایت ربات های گوگل به صفحات و بخشهای خاصی از سایت خود، از robots.txt استفاده کنید.
Robots.txt
فایل robots.txt در شاخه اصلی یا همان روت وب سایت شما قرار می گیرد. (به عنوان مثال yourdomain.com/robots.txt). این فایل به ربات های خزنده موتورهای جستجو اعلام می کند که کدام قسمت از سایت را می باید ایندکس کنند و به کدام قسمت ها نباید وارد شوند و در موارد ایندکس لحاظ نشوند. این اقدامات از طریق دستورات خاص مربوط به robots.txt انجام می گیرد.
نحوه برخورد ربات های گوگل “Googlebot” با فایل های robots.txt
- اگر ربات گوگل نتواند فایل robots.txt را برای یک سایت پیدا کند ، به جستجو در سایت ادامه می دهد.
- اگر ربات گوگل یک فایل robots.txt برای یک سایت پیدا کند ، معمولاً به پیشنهادات پایبند بوده و خزیدن سایت را ادامه می دهد.
- اگر ربات گوگل هنگام تلاش برای دسترسی به فایل robots.txt یک سایت با خطایی روبرو شود و نتواند تعیین کند که آیا این فایل وجود دارد یا خیر ، این سایت را نمی خزد.
برای بودجه خزیدن “crawl budget” بهینه کنید
بودجه خزیدن تعداد متوسط آدرس پیوندهایی است که ربات گوگل قبل از خروج از سایت شما در یک دوره زمانی مشخص مثلا یک روز در وب سایت شما خزیده است. بنابراین بهینه سازی بودجه خزیدن تضمین می کند که ربات گوگل زمان خود را برای جستجوی صفحات بی اهمیت شما هدر نمی دهد و در خطر نادیده گرفتن صفحات مهم شما قرار ندارد. بودجه خزیدن در سایت های بسیار بزرگ با ده ها هزار آدرس اینترنتی بسیار مهم است. و هرگز ایده بدی نیست که دسترسی خزنده ها به محتوایی که قطعاً برای شما اهمیتی ندارد مسدود شود. البته بودجه خزیدن در سایت هایی با تعداد صفحات پایین مثلا ۳۰۰ صفحه اهمیت چندانی ندارد و میتوان امیدوار بود که موتورهای جستجو صفحه ای را در این سایت از دست نخواهند داد. ولی در مورد سایت هایی با تعداد چندین هزار صفحه توجه به بودجه خزیدن اهمیت پیدا میکند. در این خصوص لازم است اطمینان حاصل کنید که دسترسی موتورهای جستجو به صفحاتی که دستورالعمل های دیگری در آنها اضافه کرده اید مانند برچسب های canonical یا noindex ، مسدود نکنید. به یاد داشته باشید اگر ربات گوگل از صفحه ای مسدود شود، نمی تواند دستورالعمل های آن صفحه را مشاهده کند.
به یاد داشته باشید که همه روبات هایی که در سطح وب وجود دارند فایل robots.txt را دنبال نمی کنند. افرادی که قصد بدی دارند (به عنوان مثال اسکن کننده های آدرس ایمیل) ربات هایی می سازند که از این پروتکل پیروی نمی کنند. در واقع برخی از افراد سودجو از فایل های robots.txt برای یافتن جایی که محتوای خصوصی خود را در آن قرار داده اید استفاده می کنند. اگرچه ممکن است منطقی به نظر برسد که خزنده ها را از صفحات خصوصی مانند صفحات ورود و مدیریت مسدود کنیم تا در فهرست نشان داده نشوند، اما قرار دادن محل آدرس های اینترنتی در یک فایل robots.txt که برای عموم قابل دسترسی است نیز به این معنی است که افراد دارای قصد مخرب می تواند به راحتی آنها را پیدا کند. بهتر است این صفحات را NoIndex کرده و پشت فرم ورود به سیستم قرار دهید تا اینکه آنها را در فایل robots.txt خود قرار دهید.
تعریف پارامترهای URL در گوگل سرچ کنسول GSC
برخی از سایت ها (که رایج ترین آنها در فروشگاه های اینترنتی است) با اضافه کردن پارامترهای خاصی به آدرس صفحات خود ، محتوای یکسانی را در چندین نشانی اینترنتی مختلف در دسترس قرار می دهند. اگر تا به حال به صورت آنلاین خرید کرده اید، احتمالاً جستجوی خود را از طریق فیلترها محدود کرده اید. به عنوان مثال ، شما می توانید “کفش” را در دیجی کالا جستجو کنید و سپس جستجوی خود را بر اساس اندازه، رنگ و … اصلاح کنید. با هر بار تغییر در فیلتر ها آدرس دهی کمی تغییر پیدا میکند.
گوگل چگونه می داند که کدام نسخه از نشانی اینترنتی برای جستجوگران ارائه می شود؟ گوگل به تنهایی در تشخیص آدرس دهی صفحات به خوبی کار می کند. با این حال در گوگل این امکان فراهم است که با استفاده از پارامترهای گوگل سرچ کنسول دقیقا به گوگل توضیح دهید با صفحات شما به چه شکلی رفتار نماید. به عنوان مثال می توانید “crawl no URLs with __ parameter” را استفاده کنید. شما با این دستور در اصل درخواست می کنید که این نوع از محتوا از دسترس ربات های موتورجستجو خارج شوند و این دستور می تواند منجر به حذف آن صفحات از نتایج جستجو شود. حال اگر این پارامترها که در این دستور ذکر کردید ایجاد صفحات تکراری می کنند دقیقا همان چیزی است که شما می خواهید و این صفحات از ایندکس چند باره حذف گردیده اند.
آیا ربات های خزنده موتورهای جستجو می توانند همه محتوای مهم شما را بیابند؟
اکنون که برخی از تاکتیک ها را برای اطمینان از دور ماندن خزنده های موتور جستجو از محتوای بی اهمیت خود می دانید ، بیایید با بهینه سازی هایی که می توانند به ربات های گوگل در یافتن صفحات مهم شما کمک کنند ، آشنا شویم.
گاهی اوقات یک موتور جستجو قادر است قسمت هایی از سایت شما را با خزیدن پیدا کند. اما سایر صفحات یا بخش ها ممکن است به دلایلی مبهم شوند. این مهم است که مطمئن شوید موتورهای جستجو قادر به کشف تمام محتوای موردنظر شما هستند و نه فقط صفحه اصلی شما.
آیا محتوای شما در پشت فرم های ورود پنهان شده است؟
اگر از کاربران می خواهید قبل از دسترسی به محتوای خاصی وارد سیستم شوند ، فرم ها را پر کنند یا به نظرسنجی ها پاسخ دهند ، موتورهای جستجو آن صفحات محافظت شده را نمی بینند. قطعاً خزنده وارد سیستم نمی شود.
آیا به فرم های جستجو تکیه می کنید؟
روبات ها نمی توانند از فرم های جستجو استفاده کنند. برخی افراد معتقدند که اگر یک کادر جستجو در سایت خود قرار دهند موتورهای جستجو قادر خواهند بود هر آنچه را که بازدیدکنندگان آنها جستجو می کنند ، بیابند.
آیا متن در محتوای غیر متنی پنهان شده است؟
از فرم های رسانه ای غیر متنی (تصاویر ، ویدئو ، GIF و غیره) برای نمایش متنی که می خواهید ایندکس شود استفاده نمی شود. در حالی که موتورهای جستجو در تشخیص تصاویر بهتر می شوند ، هیچ تضمینی وجود ندارد که آنها بتوانند متن روی تصاویر را بخوانند و درک کنند. همیشه بهتر است متن را در علامت صفحه وب خود اضافه کنید. و از عکس نوشته ها برای استفاده در سایت خود استفاده نکنید.
آیا موتورهای جستجو می توانند ناوبری سایت شما را دنبال کنند؟
همانطور که یک خزنده باید سایت شما را از طریق پیوندهای سایر سایت ها کشف کند ، به مسیری از پیوندها در سایت شما نیز نیاز دارد تا آن را از صفحه ای به صفحه دیگر هدایت کند. اگر صفحه ای دارید که می خواهید موتورهای جستجو آن را پیدا کنند اما از هیچ صفحه دیگری به آن پیوند ندارد ، به همان اندازه نامرئی است. بسیاری از سایت ها اشتباه مهمی را ایجاد می کنند که مسیریابی خود را به گونه ای تنظیم می کنند که برای موتورهای جستجو غیرقابل دسترسی است و مانع از ثبت نام آنها در نتایج جستجو می شود.

اشتباهات رایج ناوبری که می تواند موتورهای جستجو را از دیدن همه سایت شما باز دارد:
- داشتن ناوبری تلفن همراه که نتایج متفاوتی نسبت به ناوبری دسکتاپ شما نشان می دهد
- هر نوع ناوبری که موارد منو در HTML وجود ندارد ، مانند پیمایش های دارای جاوا اسکریپت. گوگل در خزیدن و درک جاوا اسکریپت بسیار بهتر شده است اما هنوز در این زمینه کامل نیست . مطمئن ترین راه برای اطمینان از اینکه گوگل چیزی را پیدا ، فهمیده و ایندکس می کند ، قرار دادن آن در HTML است.
- شخصی سازی یا ناوبری منحصر به فرد برای نمایش یک صفحه به نوع خاصی از بازدید کنندگان در مقایسه با تمام بازدیدکنندگان از صفحه، به عنوان نوعی از مخفی سازی “cloaking” در نظر گرفته می شود.
- فراموش کردن پیوند دادن به یک صفحه اصلی در وب سایت خود از طریق ناوبری – به یاد داشته باشید ، پیوندها مسیری هستند که خزنده ها به صفحات جدید دنبال می کنند!
به همین دلیل ضروری است که وب سایت شما دارای یک ناوبری واضح و ساختارهای آدرس دهی مفید باشد.
آیا معماری اطلاعات تمیزی دارید؟
معماری اطلاعات عمل سازماندهی و برچسب گذاری محتوا بر روی یک وب سایت برای بهبود کارایی و قابلیت یافتن کاربران است. بهترین معماری اطلاعات بصری است ، بدین معنا که کاربران نباید برای فکر کردن در وب سایت شما یا یافتن چیزی سخت فکر کنند.
آیا از نقشه سایت استفاده می کنید؟
نقشه سایت دقیقاً همان چیزی است که به نظر می رسد: لیستی از آدرس دهی های سایت شما که ربات های موتورجستجو می توانند از آنها برای کشف و فهرست بندی محتوای شما استفاده کنند. یکی از ساده ترین راه ها برای اطمینان از یافتن صفحات با اولویت اول توسط گوگل، ایجاد فایلی است که استانداردهای گوگل را برآورده کرده و آن را از طریق گوگل سرچ کنسول ارسال کنید. با اینکه داشتن نقشه سایت جایگزین ناوبری مناسب در سایت نمی شود ولی مطمئناً می تواند باعث شود تا موتورهای جستجو تمام صفحات مهم شما را دنبال کنند.
اطمینان حاصل کنید که فقط پیوندهایی را که می خواهید توسط موتورهای جستجو ایندکس شوند وارد کرده اید . همچنین مطمئن باشید که به موتورهای جستجو دستورات ثابت می دهید. به عنوان مثال در صورتی که آدرسی را از طریق robots.txt مسدود کرده اید آن نشانی اینترنتی را در نقشه سایت خود قرار ندهید. در فصل های بعدی توضیحات کامل تری را در این خصوص به شما ارائه خواهیم کرد.
اگر از هیچ سایت دیگری به سایت شما لینکی وجود ندارد، میتوانید با ارسال نقشه سایت XML خود در گوگل سرچ کنسول ایندکس شوید. هیچ تضمینی وجود ندارد که گوگل یک آدرس اینترنتی ارسال شده برای خود را در فهرست خود قرار دهد، اما ارزش امتحان کردن را دارد!
آیا موتورهای جستجو هنگام تلاش برای دسترسی به آدرس های اینترنتی شما دچار خطا می شوند؟
در فرآیند کنترل شدن پیوندهای سایت شما توسط موتورهای جستجو، یک ربات موتورجستجو ممکن است با خطاهایی روبرو شود. می توانید به گزارش “خطاهای خزیدن” “Crawl Errors” کنسول جستجوی گوگل بروید تا نشانی های اینترنتی را که ممکن است در آنها رخ دهد تشخیص دهید – این گزارش خطاهای سرور و خطاهای پیدا نشده را به شما نشان می دهد. فایل های ورود به سیستم سرور همچنین می توانند این را به شما نشان دهند، و همچنین گنجینه ای از اطلاعات دیگر مانند فرکانس خزیدن ، اما از آنجا که دسترسی و تجزیه پرونده های ورود به سیستم سرور تاکتیک پیشرفته تری است ، ما در راهنمای مبتدی به طور مفصل به آن نمی پردازیم ، و در راهنما های پیشرفته تر درباره آن به تفضیل بحث خواهیم کرد.
قبل از اینکه بتوانید با گزارش خطای خزیدن “Crawl Errors” هر کار معنی داری انجام دهید ، درک خطاهای سرور و خطاهای “پیدا نشده” مهم است.
خطاهای ۴xx: هنگامی که ربات های موتور جستجو به دلیل خطای مشتری نمی توانند به محتوای شما دسترسی پیدا کنند
خطاهای ۴xx خطاهای کلاینت (سمت کاربر) هستند، به این معنی که آدرس درخواستی دارای اشکال است یا نمی تواند انجام شود. یکی از رایج ترین خطاهای ۴xx خطای “۴۰۴ – پیدا نشد” است. این موارد ممکن است به دلیل اشتباه تایپی در پیوند، حذف صفحه یا تغییر مسیر رخ دهد. فقط برای ذکر چند مثال. وقتی موتورهای جستجو به عدد ۴۰۴ می رسند ، نمی توانند به URL دسترسی داشته باشند. وقتی کاربران ۴۰۴ را می بینند، احتمالاً ناامید شده و آنجا را ترک خواهند کرد.
کدهای ۵xx: وقتی ربات های موتور جستجو به دلیل خطای سرور نمی توانند به محتوای شما دسترسی پیدا کنند
خطاهای ۵xx خطاهای سرور هستند. بدین معنا که سروری که صفحه وب روی آن قرار دارد نتوانسته درخواست جستجوگر یا موتور جستجو برای دسترسی به صفحه را برآورده کند. در گزارش “خطای خزیدن” در کنسول جستجوی گوگل، زبانه ای به این خطاها اختصاص داده شده است. اینها معمولاً به این دلیل رخ می دهند که درخواست URL به پایان رسیده است. بنابراین ربات گوگل درخواست را رها کرده است. برای کسب اطلاعات بیشتر در مورد رفع مشکلات اتصال سرور ، اسناد گوگل را مشاهده کنید .
خوشبختانه راهی وجود دارد که به موتورهای جستجو و موتورهای جستجو بگوییم صفحه شما جابجا شده است – تغییر مسیر ۳۰۱ (دائمی).

تصور کنید که آدرس صفحه ای را از آدرس example.com/young-dogs به آدرس جدیدی در example.com/puppies/ انتقال می دهید. موتورهای جستجو و کاربران اینترنت برای دسترسی به آدرس جدید و انتقال از آدرس قدیمی به آن نیاز به یک پل ارتباطی دارند. این پل ارتباطی یک تغییر مسیر ۳۰۱ است.
| هنگام اجرای ۳۰۱: | وقتی ۳۰۱ را اجرا نمی کنید: | |
| ارزش پیوند (Link Equity) | ارزش پیوند را از محل قدیمی صفحه به آدرس جدید منتقل می کند. | بدون ۳۰۱ ، مجوز از آدرس قبلی به نسخه جدید URL منتقل نمی شود. |
| نمایه سازی (Indexing) | به گوگل کمک می کند تا نسخه جدید صفحه را پیدا و فهرست بندی کند. | وجود خطای ۴۰۴ در سایت شما به تنهایی به عملکرد جستجو آسیب نمی رساند ، اما اجازه دادن به رتبه بندی صفحات از دست رفته ۴۰۴ می تواند منجر به خارج شدن آنها از فهرست شود |
| تجربه کاربری (User Experience) | اطمینان حاصل می کند که کاربران صفحه مورد نظر خود را پیدا می کنند. | اگر به بازدیدکنندگان اجازه دهید روی پیوندهای مرده کلیک کنند ، آنها را به جای صفحات مورد نظر به صفحات خطا می برد ، که می تواند خسته کننده باشد. |
کد وضعیت ۳۰۱ به خودی خود به این معنی است که صفحه به طور دائم به مکان جدیدی منتقل شده است. بنابراین از هدایت نشانی اینترنتی به صفحات نامربوط خودداری کنید (آدرس هایی که محتوای آدرس قدیمی در آن واقعاً وجود ندارد). اگر صفحه ای برای یک پرس و جو رتبه بندی می شود و شما آن را در نشانی اینترنتی با محتوای مختلف ۳۰۱ قرار می دهید ، ممکن است از نظر رتبه پایین بیاید زیرا محتوایی که آن را به آن پرس و جو مربوط می کند دیگر وجود ندارد. تغییر مسیر های ۳۰۱ قدرتمند هستند – دقت داشته باشید که آدرس ها را با مسئولیت پذیری تغییر دهید!
شما همچنین می توانید آدرس صفحات را با تغییر مسیر ۳۰۲ تغییر دهید. اما این کار باید برای حرکت های موقت و در مواردی که انتقال ارزش ویژه پیوندها نگران کننده نیست ، محفوظ باشد. ۳۰۲ ها شبیه دور زدن جاده هستند. شما به طور موقت ترافیک را از طریق یک مسیر خاص پیش بینی می کنید ، اما برای همیشه اینطور نخواهد بود.
مراقب تغییر مسیرهای زنجیره ای باشید!
اگر برای دسترسی به یک آدرس باید چندین تغییر مسیر انجام شود، دسترسی به آن آدرس برای ربات گوگل دشوار خواهد بود. گوگل این ها را زنجیره های تغییر مسیر “redirect chains”می نامد و توصیه می کند تا آنجا که ممکن است آنها را محدود کنید. اگر example.com/1 را به example.com/2 هدایت می کنید ، بعداً تصمیم بگیرید که آن را به example.com/3 هدایت کنید ، بهتر است واسطه را حذف کرده و به سادگی example.com/1 را به example.com/3 هدایت کنید.
پس از اطمینان از بهینه سازی سایت برای موتورهای جستجو، ترتیب بعدی کار این است که مطمئن شوید ایندکس وب سایت انجام می شود.
نمایه سازی “Indexing” :موتورهای جستجو چگونه صفحات شما را تفسیر و ذخیره می کنند؟
پس از اطمینان از کنترل سایت خود توسط موتورهای جستجو و خزیده شدن صفحات وب سایت، ترتیب بعدی کار این است که مطمئن شوید وب سایت شما ایندکس می شود. فقط به این دلیل که سایت شما توسط یک موتور جستجو قابل کشف و بررسی است لزوما به این معنی نیست که در فهرست آنها ذخیره می شود. در قسمت قبل درباره خزیدن ، ما در مورد نحوه کشف صفحات وب توسط موتورهای جستجو صحبت کردیم. فهرست ها جایی است که صفحات کشف شده شما ذخیره می شوند. بعد از اینکه یک خزنده صفحه ای را پیدا کرد، موتور جستجو آن را مانند مرورگر ارائه می دهد. در فرآیند انجام این کار ، موتور جستجو محتویات آن صفحه را تجزیه و تحلیل می کند. همه این اطلاعات در فهرست خود ذخیره می شود.
برای آشنایی با نحوه ایندکس شدن (نمایه سازی) و نحوه اطمینان از اینکه سایت شما به این پایگاه داده مهم تبدیل شده است ، ادامه مطلب را بخوانید.
آیا می توانم ببینم که چگونه یک ربات موتور جستجو صفحات من را می بیند؟
بله ، نسخه ذخیره شده صفحه شما منعکس کننده آخرین باری است که ربات گوکل آن را کنترل کرده است.
گوگل صفحات وب را با فرکانس های مختلف کنترل و ذخیره می کند. سایت های معتبرتر و شناخته شده ای که مرتباً مانند سایت های خبری پست جدید ارسال می کنند، بیشتر از وب سایت بسیار مشهور کنترل می شوند.
با کلیک روی پیکان کشویی کنار URL در SERP و انتخاب “Cached” می توانید نسخه ذخیره شده صفحه خود را مشاهده کنید. همچنین می توانید نسخه متنی سایت خود را مشاهده کنید تا مشخص شود آیا محتوای مهم شما به طور موثر کنترل و ذخیره می شود.
آیا صفحات از فهرست حذف می شوند؟
بله ، صفحات را می توان از فهرست حذف کرد! برخی از دلایل اصلی حذف یک آدرس اینترنتی عبارتند از:
- نشانی اینترنتی خطای “یافت نشد” (۴XX) یا خطای سرور (۵XX) را برمی گرداند – این می تواند تصادفی باشد (صفحه منتقل شد و تغییر مسیر ۳۰۱ تنظیم نشد) یا عمدی (صفحه حذف و ۴۰۴ به منظور آن را از فهرست حذف کنید)
- آدرس اینترنتی دارای یک متا تگ noindex اضافه شده است – این نشان می تواند توسط صاحبان سایت اضافه شود تا به موتور جستجو دستور دهد صفحه را از فهرست خود حذف کند.
- نشانی اینترنتی به دلیل نقض دستورالعمل های مدیر جستجوگر وب به صورت دستی مجازات شده و در نتیجه از فهرست حذف شده است.
- قبل از اینکه بازدیدکنندگان به صفحه دسترسی داشته باشند ، با افزودن گذرواژه ، آدرس آن مسدود شده است.
اگر فکر می کنید صفحه ای در وب سایت شما که قبلاً در فهرست گوگل بود دیگر نشان داده نمی شود، می توانید از ابزار بازرسی پیوندها “URL Inspection tool” برای اطلاع از وضعیت صفحه استفاده کنید یا از Fetch as Google که دارای ویژگی “Request Indexing” است استفاده کنید. نشانی وب جداگانه را به فهرست ارسال کنید. ( ابزار “fetch” در گوگل سرچ کنسول همچنین دارای یک گزینه “render” است که به شما امکان می دهد ببینید آیا مشکلی در نحوه تفسیر گوگل از صفحه شما وجود دارد یا خیر).
به موتورهای جستجو بگویید که چگونه سایت شما را فهرست بندی کنند
دستورالعمل های متا برای روبات ها
دستورالعمل های متا (یا “برچسب های متا”) دستورالعمل هایی هستند که می توانید در مورد نحوه برخورد با صفحه وب خود به موتورهای جستجو بدهید.
می توانید به خزنده های موتورهای جستجو مواردی مانند “این صفحه را در نتایج جستجو فهرست نکنید” یا “هیچگونه ارزش پیوند را به هیچ پیوندی روی صفحه منتقل نکنید” بگویید. این دستورالعمل ها از طریق برچسب های روبات ها در صفحات HTML شما (بیشتر مورد استفاده) یا از طریق برچسب X-Robots در هدر HTTP اجرا می شود.
متا تگ روبات ها
متا تگ روبات ها می توانند در صفحه HTML وب شما استفاده شوند. این دستورات می توانند جلوی ورود تمام یا برخی از موتورهای جستجو به وب سایت شما را بگیرند. موارد زیر متداول ترین دستورالعمل های متا به همراه موارد استفاده آنها هستند.
index/noindex : به موتورها می گوید که آیا صفحه باید کنترل شود و در فهرست موتورهای جستجو برای بازیابی نگهداری شود. اگر از “noindex” استفاده کنید ، با ربات ها ارتباط برقرار می کنید که می خواهید صفحه از نتایج جستجو حذف شود. به طور پیش فرض ، موتورهای جستجو فرض می کنند که می توانند همه صفحات را فهرست بندی کنند ، بنابراین استفاده از مقدار “index” غیر ضروری است.
چه زمانی باید از آن استفاده کنید: اگر سعی می کنید صفحات بی محتوا را از فهرست گوگل سایت خود کم کنید (به عنوان مثال: صفحات نمایه ایجاد شده توسط کاربر) ، اما همچنان می خواهید آنها برای بازدیدکنندگان قابل دسترسی باشد ، علامت گذاری یک صفحه به عنوان “noindex” را انتخاب کنید.
follow/nofollow : به موتورهای جستجو می گوید که پیوندهای صفحه باید دنبال شوند یا دنبال نشوند. نتایج “Follow” به دنبال ربات هایی است که پیوندهای صفحه شما را دنبال کرده و ارزش لینک را به آن پیوندها منتقل می کنند. یا اگر از “nofollow” استفاده می کنید ، موتورهای جستجو هیچ پیوندی را پیوند نمی دهند یا به پیوندهای موجود در صفحه منتقل نمی کنند. به طور پیش فرض ، فرض می شود که همه صفحات دارای ویژگی “follow” هستند.
چه زمانی باید از آن استفاده کنید: nofollow اغلب همراه با noindex هنگام تلاش برای جلوگیری از ایندکس شدن صفحه و همچنین جلوگیری از دنبال کردن پیوندهای موجود در صفحه توسط ربات های موتور جستجو استفاده می شود.
noarchive : برای محدود کردن موتورهای جستجو در ذخیره کردن کپی از صفحه استفاده می شود. به طور پیش فرض ، موتورها نسخه های قابل مشاهده ای از تمام صفحاتی را که فهرست بندی کرده اند ، حفظ می کنند و از طریق پیوند ذخیره شده در نتایج جستجو برای جستجوگران قابل دسترسی است.
چه زمانی باید از آن استفاده کنید: اگر یک سایت فروشگاه اینترنتی را اداره می کنید و قیمت های شما به طور مرتب تغییر می کند ، ممکن است برچسب noarchive را برای جلوگیری از مشاهده قیمت های قدیمی جستجوکنندگان در نظر بگیرید.
تگ X-Robots
اگر می خواهید موتورهای جستجو را در مقیاس وسیع مسدود کنید؛ تگ x-robots در هدر HTTP آدرس شما استفاده می شود و انعطاف پذیری و عملکرد بیشتری نسبت به متا تگ ها دارد زیرا می توانید از عبارات معمولی استفاده کنید ، فایل های غیر HTML را مسدود کرده و برچسب های noindex در سراسر سایت را اعمال کنید.
به عنوان مثال ، شما به راحتی می توانید کل پوشه ها یا انواع فایل (مانند example.com/no-bake/oldrecipes-to-noindex) را حذف کنید:
Header set X-Robots-Tag “noindex, nofollow”
مشتقات مورد استفاده در متا تگ روبات ها می توانند در برچسب X-Robots نیز استفاده شوند.
یا انواع فایل های خاص (مانند PDF):
Header set X-Robots-Tag “noindex, nofollow”
برای کسب اطلاعات بیشتر در مورد تگ های Meta Robot ، می توانید آن را از قسمت Google’s Robots Meta Tag Specifications بیشتر مطالعه کنید.
نکته درباره وردپرس:
پس از ورود به محیط مدیریت در داشبورد> تنظیمات> خواندن ، مطمئن شوید که کادر “نمایش به موتورهای جستجو” علامت زده نشده است . این تیک مانع از ورود موتورهای جستجو از طریق فایل robots.txt به سایت شما می شود!
درک روش های مختلفی که می توانید بر کنترل موتورهای جستجو و ایندکس شدن اطلاعات تأثیر بگذارید به شما کمک می کند از مشکلات رایجی که می توانند از پیدا شدن صفحات مهم شما ممانعت کنند، جلوگیری کنید.
رتبه بندی “Ranking”: موتورهای جستجو چگونه آدرس های اینترنتی را رتبه بندی می کنند؟
چگونه موتورهای جستجو اطمینان می یابند که وقتی شخصی یک پرس و جو را در نوار جستجو وارد می کند، در عوض نتایج مربوطه را دریافت می کند؟ این فرایند به عنوان رتبه بندی یا ترتیب نتایج جستجو با بیشترین ارتباط با حداقل یک پرس و جو شناخته می شود.

برای تعیین ارتباط ، موتورهای جستجو از الگوریتم ها ، فرایند یا فرمول استفاده می کنند که به موجب آن اطلاعات ذخیره شده به روش های معنی دار بازیابی و مرتب می شوند. این الگوریتم ها در طول سال ها تغییرات زیادی را به منظور بهبود کیفیت نتایج جستجو انجام داده اند. به عنوان مثال ، گوگل هر روز تنظیمات الگوریتم را انجام می دهد – برخی از این به روز رسانی ها تغییراتی جزئی هستند ، در حالی که برخی دیگر از به روزرسانی ها در الگوریتم و بسیار اصلی و گسترده هستند که برای حل مشکل خاصی مانند پنگوئن برای مقابله با پیوند هرزنامه استفاده می شوند.
چرا الگوریتم ها اینقدر تغییر می کند؟ آیا گوگل فقط سعی می کند ما را سر کار نگه دارد؟ در حالی که گوگل همیشه توضیح نمی دهد که چرا آنها کاری را انجام می دهند، ما می دانیم که هدف گوگل از تنظیم الگوریتم بهبود کیفیت کلی جستجو است. به همین دلیل است که گوگل در پاسخ به سؤالات به روز رسانی الگوریتم با چیزی در این زمینه پاسخ می دهد: “ما مرتباً به روزرسانی های با کیفیت انجام می دهیم.” این نشان می دهد که اگر سایت شما پس از تعدیل الگوریتم دچار مشکل شد، آن را با دستورالعمل های کیفیت گوگل Google’s Quality Guidelines یا دستورالعمل های رتبه بندی کیفیت جستجو Search Quality Rater Guidelines مقایسه کنید، هر دو از نظر آنچه موتورهای جستجو می خواهند بسیار گویاست.
موتورهای جستجو چه می خواهند؟
موتورهای جستجو همیشه یک چیز را می خواهند: ارائه پاسخ های مفید به سوالات جستجوگر در مفیدترین قالب ها. اگر این درست است ، پس چرا به نظر می رسد که SEO اکنون متفاوت از سالهای گذشته است؟
در مورد اینکه کسی یک زبان جدید یاد می گیرد به آن فکر کنید.
در ابتدا ، درک آنها از زبان بسیار ابتدایی است. با گذشت زمان ، درک آنها عمیق تر می شود و آنها معانی را یاد می گیرند. معنای پشت زبان و رابطه بین کلمات و عبارات. درنهایت ، با تمرین کافی ، دانش آموز زبان را آنقدر خوب می داند که حتی می تواند تفاوت های ظریف را درک کند و قادر است به سوالات حتی مبهم یا ناقص پاسخ دهد.
هنگامی که موتورهای جستجو تازه در حال یادگیری زبان ما بودند ، بازی سیستم با استفاده از ترفندها و تاکتیک هایی که در واقع بر خلاف دستورالعمل های کیفیت است بسیار آسان تر بود. برای مثال کلمات کلیدی را پر کنید. اگر می خواهید برای یک کلمه کلیدی خاص مانند “جوک های خنده دار” رتبه بندی کنید ، ممکن است کلمات “جوک های خنده دار” را چندین بار به صفحه خود اضافه کنید و آن کار را جسورانه ادامه دهید. به این امید که رتبه خود را برای آن عبارت افزایش دهید:
به جوک های خنده دار خوش آمدید ! ما خنده دار ترین جوک های جهان را می گوییم . جوک های خنده دار سرگرم کننده و دیوانه کننده هستند . شوخی خنده دار شما در انتظار است. بنشینید و جوک های خنده دار بخوانید زیرا جوک های خنده دار می تواند شما را خوشحال و بامزه تر کند . برخی از جوک های خنده دار مورد علاقه خنده دار .
این تاکتیک باعث ایجاد تجربیات وحشتناک کاربران شد و به جای خندیدن به شوخی های خنده دار، افراد با متن آزاردهنده و سخت خواندنی بمباران شدند. ممکن است در گذشته کار کرده باشد، اما این هرگز آن چیزی نیست که موتورهای جستجو می خواهند.
پیوندها نقش مهمی در سئو دارند
وقتی در مورد پیوندها صحبت می کنیم ، می توانیم دو معنی را منظور کنیم. بک لینک ها “Backlinks” یا پیوندهای ورودی “inbound links” پیوندهایی از سایر وب سایت ها که به وب سایت شما اشاره می کنند، در حالی که پیوندهای داخلی “internal” پیوندهایی در سایت شما هستند که به صفحات دیگر شما (در همان سایت) اشاره می کنند.

پیوندها در طول تاریخ نقش زیادی در سئو داشته اند. در اوایل ، موتورهای جستجو به کمک نیاز داشتند تا بفهمند کدام آدرس ها نسبت به سایرین قابل اعتمادتر هستند تا به آنها در تعیین نحوه رتبه بندی نتایج جستجو کمک کنند. محاسبه تعداد پیوندهایی که به هر سایتی اشاره می کنند به آنها در این امر کمک کرد.
بک لینک ها بسیار شبیه به بازاریابی زبانی (دهان به دهان) در زندگی واقعی هستند. بیایید از یک کافی شاپ فرضی ، قهوه کهن، به عنوان مثال استفاده کنیم:
- ارجاع دیگران = نشانه خوب قدرت
- مثال: بسیاری از افراد مختلف به شما گفته اند که قهوه کهن بهترین قهوه در شهر است
- ارجاعات از جانب خود = مغرضانه ، بنابراین نشانه خوبی از اقتدار نیست
- مثال: قهوه کهن ادعا می کند که بهترین قهوه در شهر است
- ارجاع از منابع نامربوط یا با کیفیت پایین = نشانه خوبی از قدرت نیست و حتی می تواند شما را به عنوان هرزنامه پرچم گذاری کند
- مثال: قهوه کهن هزینه کرد تا افرادی که هرگز از کافی شاپ او دیدن نکرده اند به دیگران بگویند که چقدر خوب است.
- بدون ارجاع = اختیار نامشخص
- مثال: قهوه کهن خوب است ، اما شما نتوانستید کسی را پیدا کنید که نظری داشته باشد بنابراین نمی توانید مطمئن باشید.
به همین دلیل PageRank ایجاد شد. PageRank (بخشی از الگوریتم اصلی گوگل) یک الگوریتم تجزیه و تحلیل پیوند است که به نام یکی از بنیانگذاران گوگل ، لری پیج “Larry Page” نامگذاری شده است. PageRank با اندازه گیری کیفیت و کمیت پیوندهایی که به آن اشاره می کنند اهمیت یک صفحه وب را برآورد می کند. فرض بر این است که هرچه یک صفحه وب مرتبط ، مهم و قابل اعتماد باشد ، پیوندهای بیشتری به دست خواهد آورد.
هرچه بک لینک های طبیعی تری از وب سایت های معتبر (معتمد) داشته باشید ، شانس شما برای رتبه بندی بیشتر در نتایج جستجو بهتر است.
نقش محتوا در سئو
موتورهای جستجو اگر جستجوگران را به چیزی هدایت نکنند ، پیوندها فایده ای نخواهند داشت. اینکه چیزی محتواست! محتوا فراتر از کلمات است ؛ این چیزی است که باید توسط جستجوگران مصرف شود – محتوای ویدیویی ، محتوای تصویری و البته متن ها وجود دارند. اگر موتورهای جستجو ماشین های پاسخگویی هستند ، محتوا وسیله ای است که موتورها این پاسخ ها را ارائه می دهند.
هر زمان که کسی جستجویی را انجام می دهد هزاران نتیجه ممکن وجود دارد. بنابراین موتورهای جستجو چگونه تصمیم می گیرند که جستجوگر کدام صفحات با ارزش را پیدا کند؟ بخش عمده ای از تعیین رتبه صفحه شما برای یک پرس و جوی مشخص شده این است که محتوای صفحه شما چقدر مطابق با درخواست است. به عبارت دیگر ، آیا این صفحه با کلماتی که جستجو شده است مطابقت دارد و به جستجوگر در پیدا کردن پاسخ خود کمکی می کند؟
به دلیل تمرکز بر رضایت کاربر و انجام وظایف موتورهای جستجو، هیچ معیار محکمی در مورد مقدار محتوای شما، اینکه چند بار حاوی کلمه کلیدی یا مواردی که در تگ های سربرگ خود قرار می دهید وجود ندارد. همه آنها می توانند در نحوه عملکرد یک صفحه در جستجو نقش داشته باشند، اما تمرکز باید بر کاربرانی باشد که مطالب را می خوانند.
امروزه ، با صدها یا حتی هزاران سیگنال رتبه بندی، سه مورد اول نسبتاً ثابت هستند: پیوندها به وب سایت شما (که به عنوان سیگنال های اعتبار شخص ثالث عمل می کند)، محتوای روی صفحه (محتوای باکیفیت که هدف یک جستجوگر را برآورده می کند) و رنک برین “RankBrain”.
رنک برین “RankBrain” چیست؟
رنگ برین “RankBrain” از الگوریتم های اصلی گوگل و نوعی هوش مصنوعی است. هوش مصنوعی یک برنامه کامپیوتری است که در طول زمان نتایج خود را از طریق مشاهدات بهبود می بخشد. به عبارت دیگر این الگوریتم دائما در حال یادگیری است و در نتیجه دائماً نتایج آن در حال بهبود است.
به عنوان مثال اگر رنک برین متوجه شود که یک آدرس دارای رتبه پایین تری نسبت به رقبای خود است و دیگر آدرس ها نتایج بهتری را به جستجوگران ارائه می دهد، می توانید مطمئن باشید که رنک برین این نتایج را مجدداً تتنظیم کرده و نتایج مرتبط تر و مفید تر برای کاربر را در رتبه های بالاتر قرار می دهد.
مانند بسیاری از موارد دیگر در موتورهای جستجو، ما دقیقاً نمی دانیم که رنک برین شامل چه مواردی است. اما بر اساس آنچه از مقالات و نشریات مهم بر می آید ظاهرا این مورد در گوگل نیز محرمانه است و بیشتر افراد چیزی از آن نمیدانند.
این ها برای SEO چه معنایی دارد؟
از آنجا که گوگل برای ارتقاء مرتبط ترین و مفیدترین مطالب ، از رنک برین استفاده می کند، ما باید بیش از هر زمان دیگری بر تحقق هدف جستجو تمرکز کنیم. بهترین اطلاعات و تجربه ممکن را برای جستجوگرانی که ممکن است در صفحه شما قرار بگیرند، ارائه دهیم. و شما با خواندن این مقاله اولین قدم بزرگ را برای عملکرد خوب خود در جهان رنک برین برداشته اید.
معیارهای تعامل : همبستگی ، علیت ، یا هر دو؟
با رتبه بندی گوگل، معیارهای تعامل “Engagement metrics” به احتمال زیاد بخشی از همبستگی “correlation” و بخشی از علیت “causation” است.
وقتی می گوییم معیارهای مشارکت ، منظور ما داده هایی است که نحوه تعامل جستجوگران با سایت شما را از نتایج جستجو نشان می دهد. این شامل مواردی مانند:
- کلیک “Clicks” (بازدید از جستجو)
- زمان روی صفحه “Time on page” (مدت زمانی که بازدیدکننده قبل از خروج از صفحه در آن صرف کرده است)
- نرخ پرش “Bounce rate“(درصد تمام جلسات وب سایت که کاربران تنها یک صفحه را مشاهده کرده اند)
- Pogo-sticking (کلیک روی یک نتیجه ارگانیک و سپس بازگشت سریع به SERP برای انتخاب نتیجه دیگر)
بسیاری از آزمایش ها که توسط شرکت های بزرگی در دنیا بر روی رفتار موتورهای جستجو انجام شده نشان داده است که معیارهای مشارکت با بدست آورن نتایج برتر ارتباط دارد ، اما در مورد علت این مورد مباحث جدی و زیادی انجام شده است. آیا معیارهای مشارکت خوب فقط نشان دهنده سایت های دارای رتبه بالا است؟ یا آیا سایت ها به دلیل داشتن معیارهای مشارکت خوب رتبه بالایی دارند؟
آنچه گوگل گفته است
در شرایطی که گوگل هیچ گاه در جایی اعلام نکرده است که فهرست خود را بر اساس رتبه بندی مستقیم بر اساس بازدید و کلیک دسته بندی می کند، اما واضح است که در نمایش SERP برای جستجوهای خاص کاملاً از آن استفاده می کنند.
به گفته اودی منبر ، مدیر سابق کیفیت جستجو در گوگل :
“رتبه بندی به خودی خود تحت تأثیر داده های کلیک قرار می گیرد. اگر متوجه شویم که برای یک پرس و جو خاص ، ۸۰ درصد مردم روی شماره ۲ و فقط ۱۰ درصد روی شماره ۱ کلیک می کنند ، پس از مدتی متوجه می شویم که احتمالاً شماره ۲ موردی است که مردم می خواهند ، بنابراین آن را تغییر می دهیم. “
نظر دیگری از مهندس سابق گوگل ادموند لاو این را تأیید می کند:
“کاملاً واضح است که هر موتور جستجوی منطقی از داده های کلیک بر روی نتایج خود استفاده می کند تا در رتبه بندی برای بهبود کیفیت نتایج جستجو قرار گیرد. مکانیسم واقعی نحوه استفاده از داده های کلیک اغلب اختصاصی است. اما گوگل به وضوح نشان می دهد که از داده های کلیک با ثبت اختراعات خود در سیستم هایی مانند موارد محتوا با رتبه بندی استفاده می کند. “
از آنجا که گوگل نیاز به حفظ و ارتقاء کیفیت جستجو دارد ، به نظر می رسد معیارهای مشارکت فراتر از همبستگی هستند، اما به نظر می رسد که گوگل از معیارهای مشارکت به عنوان “سیگنال رتبه بندی” نام نمی برد ، زیرا این معیارها برای بهبود کیفیت جستجو استفاده می شوند. رتبه پیوندهای فردی فقط محصول جانبی آن است.
چه آزمایشاتی تایید کرده است
آزمایش های مختلف تأیید کرده اند که گوگل ترتیب SERP را در پاسخ به مشارکت جستجوگران تنظیم می کند:
- آزمایش رند فیشکین در سال ۲۰۱۴ منجر به این شد که پس از ۲۰۰ نفر که روی آدرس اینترنتی SERP بر روی آدرس کلیک کردند ، به رتبه ۷ صعود کرد. جالب اینجاست که به نظر می رسد بهبود رتبه در مکان افرادی که از پیوند دیدن کرده اند جدا باشد. رتبه بندی در ایالات متحده ، جایی که بسیاری از شرکت کنندگان در آن قرار داشتند ، افزایش یافت ، در حالی که در صفحه گوگل کانادا ، گوگل استرالیا و غیره در صفحه پایین تر بود.
- در آزمایش لری کیم به نظر می رسد با استفاده از رنک برین، الگوریتم های هوش مصنوعی گوگل رتبه صفحاتی را که افراد زمان زیادی برای آنها صرف نمی کنند به نسبت دیگر صفحات پایین می آورد.
- آزمایش دارن شاو تأثیر رفتار کاربر را در نتایج جستجوی محلی و بسته های نقشه نشان داده است.
از آنجا که معیارهای مشارکت کاربر به وضوح برای تنظیم SERP ها از نظر کیفیت مورد استفاده قرار می گیرد و موقعیت رتبه بندی به عنوان محصول جانبی تغییر می کند، می توان گفت که سئو باید برای تعامل بهینه سازی کنند . تعامل کیفیت عینی صفحه وب شما را تغییر نمی دهد، بلکه ارزش شما را برای جستجوگران نسبت به سایر نتایج آن پرس و جو تغییر می دهد. به همین دلیل است که پس از هیچ تغییری در صفحه شما و بک لینک های آن ، اگر رفتارهای جستجوگران نشان دهد که صفحات دیگر را بیشتر می پسندند، ممکن است رتبه بندی آنها کاهش یابد.
از نظر رتبه بندی صفحات وب، معیارهای تعامل مانند یک بررسی کننده واقعیت عمل می کنند. عوامل عینی مانند پیوندها و محتوا ابتدا صفحه را رتبه بندی می کنند، سپس معیارهای مشارکت به گوگل کمک می کند که در صورت عدم دریافت صحیح آن را تنظیم کند.
تکامل نتایج جستجو
زمانی که موتورهای جستجو فاقد پیچیدگی های امروزی بودند ، اصطلاح “۱۰ پیوند آبی” برای توصیف ساختار مسطح SERP ابداع شد. هر زمان که جستجو انجام می شد ، گوگل صفحه ای را با ۱۰ نتیجه ارگانیک ، هر کدام در یک قالب ، باز می گرداند.
در این صفحه جستجو ، حفظ جایگاه شماره یک جام مقدس سئو بود. اما بعد اتفاقی افتاد. گوگل شروع به افزودن نتایج در قالب های جدید در صفحات نتایج جستجوی خود ، به نام ویژگی های SERP کرد . برخی از این ویژگی های SERP عبارتند از:
- تبلیغات پولی
- تکه های ویژه
- مردم همچنین جعبه ها را می پرسند
- بسته محلی (نقشه)
- پنل دانش
- پیوندهای سایت
و گوگل دائماً موارد جدیدی را اضافه می کند. آنها حتی SERP های بدون نتیجه را آزمایش کردند ، پدیده ای که در آن تنها یک نتیجه از نمودار دانش روی SERP نمایش داده شد و هیچ نتیجه ای در زیر آن وجود نداشت به جز گزینه ای برای مشاهده نتایج بیشتر.
افزودن این ویژگی ها به دو دلیل اصلی باعث وحشت اولیه شد. برای اولین بار ، بسیاری از این ویژگی ها باعث شد تا نتایج ارگانیک در SERP بیشتر کاهش یابد. محصول جانبی دیگر این است که جستجوگران کمتری بر روی نتایج ارگانیک کلیک می کنند زیرا به سئوالات بیشتری در خود SERP پاسخ داده می شود.
پس چرا گوگل این کار را می کند؟ همه چیز به تجربه جستجو برمی گردد. رفتار کاربر نشان می دهد که برخی از درخواست ها با قالب های مختلف محتوا بهتر ارضا می شوند. توجه کنید که چگونه انواع مختلف ویژگی های SERP با انواع مختلف درخواست پرس و جو مطابقت دارد.
ما در فصل بعد بیشتر در این مورد صحبت خواهیم کرد، اما فعلاً مهم است بدانید که پاسخ ها را می توان در طیف گسترده ای از فرمت ها به جستجوگران تحویل داد. و اینکه چگونه محتوای خود را ساختار می دهید می تواند بر فرمت نمایش داده شده در جستجو تأثیر بگذارد.
جستجوی محلی
یک موتور جستجو مانند گوگل دارای فهرستی اختصاصی از مشاغل محلی است که از آن نتایج جستجوی محلی خود را ایجاد می کند.
اگر در حال انجام سئو برای یک شغل محلی برای هستید که مکان فیزیکی دارد و مشتریان می توانند از آن دیدن کنند مانند یک دندانپزشکی و یا برای کسب و کاری سئو انجام می دهید که به بازدید از مشتریان خود خواهد رفت مانند لوله کشی اطمینان حاصل کنید که این مورد در سایت شما وجود دارد و در لیست مشاغل گوگل ثبت شده است. توجه داشته باشید که این امکان در حال حاضر در ایران به دلیل تحریم دارای محدودیت های بسیاری است.
در مورد نتایج جستجوی محلی ، گوگل از سه عامل اصلی برای تعیین رتبه بندی استفاده می کند:
- ارتباط “Relevance”
- فاصله “Distance”
- برجستگی “Prominence”
ارتباط
ارتباط این است که یک تجارت محلی چقدر با آنچه جستجوگر بدنبال آن است مطابقت دارد. برای اطمینان از اینکه کسب و کار تمام تلاش خود را می کند تا مربوط به جستجوگران باشد ، اطمینان حاصل کنید که اطلاعات کسب و کار به طور کامل و دقیق پر شده است.
فاصله
گوگل از موقعیت جغرافیایی شما برای ارائه بهتر نتایج محلی استفاده می کند. نتایج جستجوی محلی نسبت به مجاورت بسیار حساس است، که به مکان جستجوگر و یا مکان مشخص شده در پرس و جو اشاره می کند (اگر جستجوگر یکی از آنها را داشته باشد).
نتایج جستجوی ارگانیک نسبت به مکان جستجوکننده حساس است ، اگرچه به ندرت به اندازه نتایج بسته محلی بیان می شود.
برجستگی یا برتری “Prominence”
گوگل با برجستگی به عنوان یک عامل ، به دنبال پاداش به مشاغلی است که در دنیای واقعی شناخته شده هستند. علاوه بر برجستگی آفلاین یک کسب و کار ، گوگل برای تعیین رتبه محلی به برخی عوامل آنلاین نیز نگاه می کند ، مانند:
بررسی ها
تعداد نظرات گوگل که یک کسب و کار محلی دریافت می کند ، و احساسات این بررسی ها ، تأثیر قابل توجهی در رتبه بندی آنها در نتایج محلی دارد.
استناد
“نقل قول تجاری” یا “فهرست کسب و کار” یک مرجع مبتنی بر وب به “NAP” مشاغل محلی (نام ، آدرس ، شماره تلفن) در یک پلت فرم محلی (Yelp ، Acxiom ، YP ، Infogroup ، Localeze و غیره) است.
رتبه بندی محلی تحت تأثیر تعداد و ثبات استنادات مشاغل محلی است. گوگل برای ایجاد پیوسته فهرست مشاغل محلی خود از منابع مختلفی استفاده می کند. وقتی گوگل چندین نام ثابت به نام ، محل و شماره تلفن مشاغل پیدا می کند ، “اعتماد” گوگل به اعتبار آن داده ها را تقویت می کند. این امر منجر به این می شود که گوگل بتواند کسب و کار را با درجه اطمینان بالاتری نشان دهد. گوگل همچنین از اطلاعات سایر منابع موجود در وب مانند پیوندها و مقالات استفاده می کند.
رتبه بندی ارگانیک
بهترین شیوه های سئو در مورد سئو محلی نیز صدق می کند، زیرا گوگل هنگام تعیین رتبه محلی، موقعیت وب سایت را در نتایج جستجوی ارگانیک در نظر می گیرد.
در فصل بعدی ، بهترین شیوه های درون صفحه ای را یاد خواهید گرفت که به گوگل و کاربران کمک می کند مطالب شما را بهتر درک کنند.
مشارکت محلی
اگرچه مشارکت محلی توسط گوگل به عنوان یک عامل رتبه بندی محلی ذکر نشده است ، نقش مشارکت تنها با گذشت زمان افزایش می یابد. گوگل همچنان با ترکیب داده های دنیای واقعی مانند زمان های رایج برای بازدید و مدت زمان متوسط بازدیدها ، نتایج محلی را غنی می کند …
… و حتی این امکان را برای جستجوگران فراهم می کند که سوالات تجاری را بپرسند!

بی شک در حال حاضر بیش از هر زمان دیگری ، نتایج محلی تحت تأثیر داده های دنیای واقعی است. این تعامل، نحوه تعامل جستجوگران و پاسخگویی آنها به مشاغل محلی است ، نه اطلاعاتی کاملاً ثابت (و قابل بازی) مانند پیوندها و نقل قول ها.
از آنجا که گوگل می خواهد بهترین و مرتبط ترین مشاغل محلی را به جستجوگران ارائه دهد ، منطقی است که آنها از معیارهای مشارکت در زمان واقعی برای تعیین کیفیت و ارتباط استفاده کنند.
نیازی به دانستن نکات و الگوریتم های الگوریتم گوگل نیست (این یک راز باقی مانده است!) ، اما در حال حاضر شما باید از دانش پایه اولیه در مورد نحوه جستجو ، تفسیر ، ذخیره و رتبه بندی محتوا توسط موتور جستجو مطلع باشید. با داشتن این دانش ، در مرحله بعد در مورد انتخاب کلیدواژه هایی که محتوای شما (تحقیقات در خصوص کلمات کلیدی) مورد هدف قرار می دهد صحبت خواهیم کرد.
این مقاله برگرفته از وب سایت MOZ.com است.


